微信Mars策略分析
本文最后更新于:2017年5月13日 凌晨
前几年在微信工作时,参加一些内部会议当时也有做了相关简要整理: Android网络,前端时间也有总结了微信的心跳机制,今天主要是对已开源的Mars进行窥探。如果对目前行业中互联网现状感兴趣也可以留意下这里
Mars是微信已经开源的小数据传输解决方案与一些客户端开发常用工具集项目: https://github.com/Tencent/mars
具体部分可以参考官方图片:
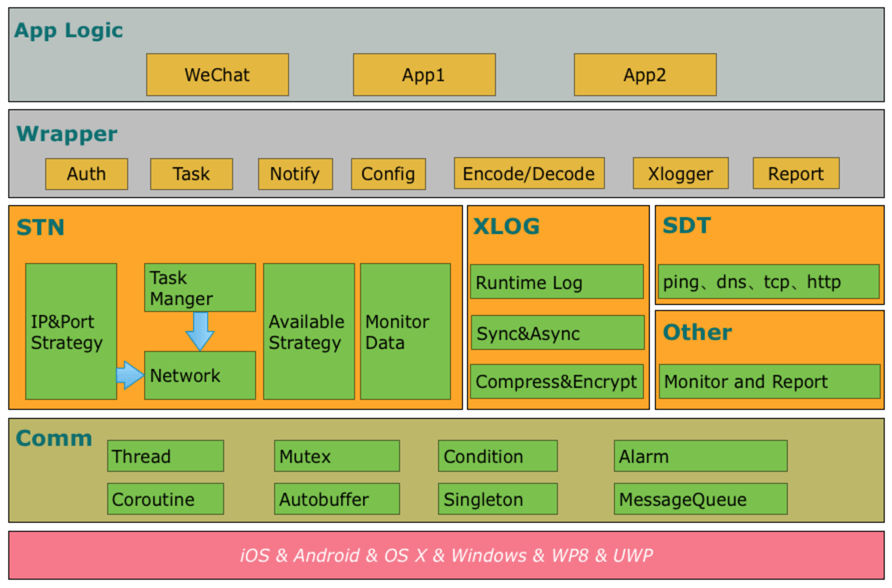
- Commn: 网络组件
- STN: 信令网络(小数据传输),Mars的主要部分
- SDT: 网络争端组件
- CDN: 数据网络(大数据传输)(由于耦合腾讯CDN服务,因此没有开源)
- XLOG: 日志组件
- 终端质量平台
I. STN模块
- 要求: 高可用、高性能、低负载、容灾性
- 架构: 稳定、简化
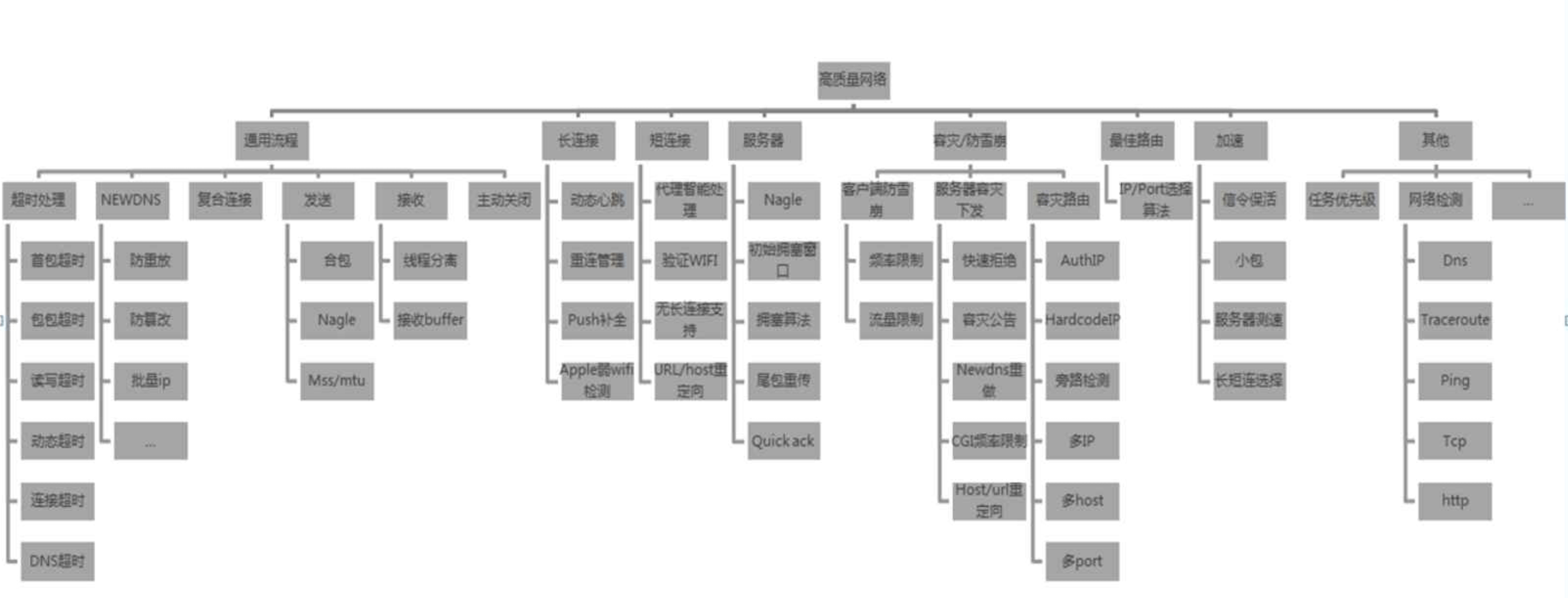
STN特征
1. 对比
相比与IOS的AFNetworking、Android的Retrofit、OkHttp而言
- STN跨平台
- STN优化是基于Socket层(大多数其他的库都是HTTP层),因此能达到更深入的优化
- STN更适用于小数据传输,信令网络
2. 特点
- 包含两种通道: 长连接(性能要求高的请求),短连接(普通一来一回的请求),对于上层业务而言只需要关注业务
- 更适合做移动互联网组件: 前后台、活跃态、休眠、省电、省流量。DNS防劫持,负载,容灾
- 更多: 数据监控(网络情况),参数配置
STN连接策略
建立连接
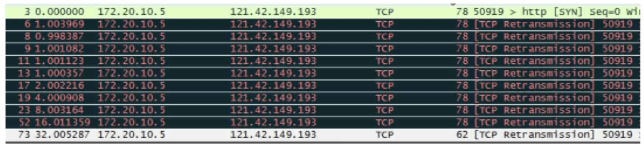
1. 连接超时情景
- 连不通: 无论如何都差不多
- 被劫持/服务器故障: 希望更快的返回,以便于更换IP端口快速查找可用资源
- 弱网络,基站繁忙、连接信号弱,丢包率高: 希望超时更长些,延时高,丢包率高,等长一点,重试多些(由于换IP/端口无用)
2. 连接超时考量点
可用性,网络敏感性,用户体验(< 1min)
3. 连接超时间隔策略
- Linux与Android: 指数递增(0,2,4,8,16)

- IOS: 优化后的指数递增(1,1,1,1,1,2,4,8,16)
- STN: 策略权衡相对适用于微信(可能有些应用需要更高的敏感性): 10s
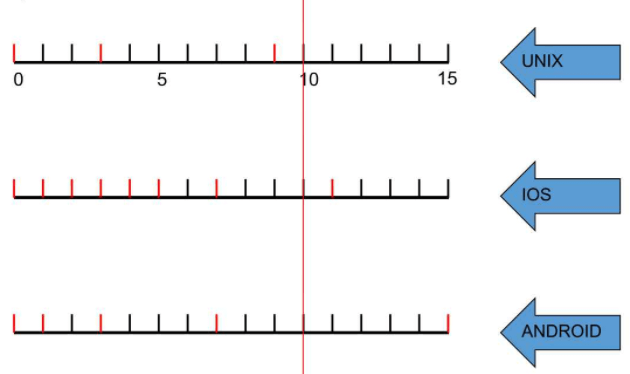
STN连接超时间隔10s的原因:
- 占用重试频率比较高的间隔
- 10s之后,Android需要经过5s才能发起下一次重试(需要相对长无效的等待时间)
4. STN连接效率策略
- 目标: 快速找到有效可用的IP/端口资源
常见策略:
- 串行连接: 资源占用少、无服务器负载问题、超时选择困难、最慢可用选择
- 并发连接: 网络资源竞争(复杂度、性能消耗)、服务器负责(成倍增加)、最快可用(提高效率)
STN策略:
- STN复合连接: 更快的找到可用并不增加服务器负载
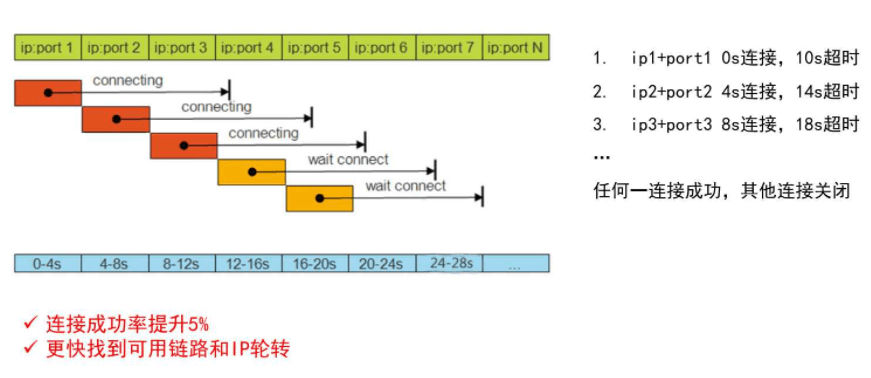
5. 建立连接其他优化
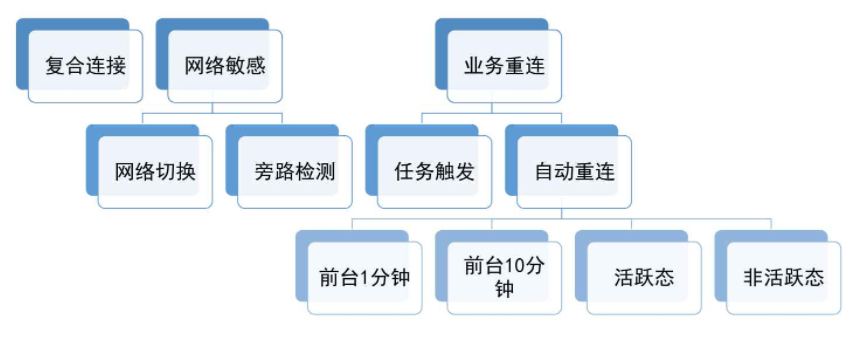
维持连接
1. 优化探究
- 链路层: 需要在不可靠的物理设备的基础上,实现节点与节点间可靠的信息传输,一般使用混合自动重传请求(
HARQ(Hybrid Automatic Repeat reQuest) = FEC(前馈式错误修正) + ARQ(自动重传请求)),其能够使得前一个失败的尝试中存下有用资讯供之后的解码使用,这个需要手机与RNC都支持 - 传输层(TCP层): 需要基于不可靠的链路做端与端之间每个TCP数据包的可靠传输,是通过超时和重传做到的,在发送数据时设定一个定时器,定时器溢出时还没有收到ACK,则重传该数据
应用层:
- 更应该为用户体验考虑(尽可能提高成功率)
- 保障弱网络下的可用性
- 具有网络敏感性,快速的发现新链路
2. 读写超时间隔策略
TCP确认失败的时间: Android系统16min, IOS系统1min~3.5min
- UNIX的指数退避: [1,3,6,12,24,48,64,64…]

- Android: (OPPO手机数据,前部分更积极) [0.25,0.5,1,2,4,8,16,32,64,64,64…]
- IOS: (前部分更积极,后部分也很积极) [1,1,1,2,4.5,9,13.5,26,26…]
P.S. Unix中的
指数退避的间隔是取决于 RTT,而RTT本身由于受网络路由、流量等影响,有极为复杂的测量算法(平滑算法、Karn算法、Jacbson算法))。
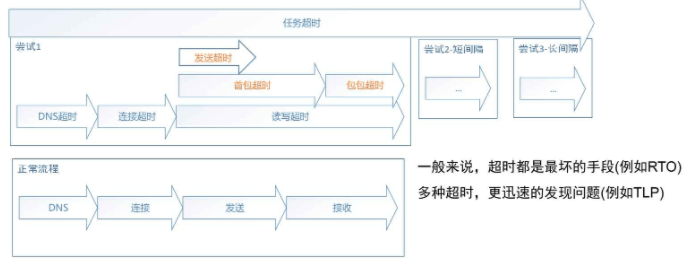
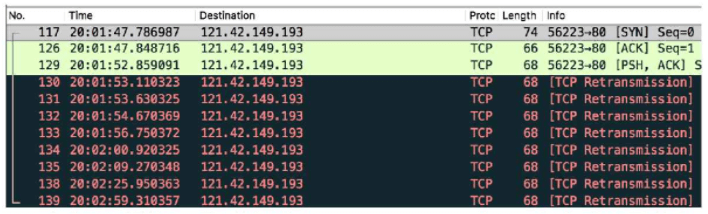
STN读写超时(多级超时方案)(应用层读写超设计):
- 目标: 高性能(用户体验以及尽可能的提高成功率)、可用性(弱网场景)、敏感性(网络敏感性,快速发现新链路)
- 做法: 将原有连接断掉,重新选择IP与端口
- 作用: 减少无效的等待时间(因为重传间隔越来越大,断连重连,使TCP层保持积极重连间隔),增加重试次数;切换链路,在较大波动/严重拥塞,通过更换连接(IP与端口)获得更好的性能
STN读写超时具体多级超时方案:
- 总读写超时: 请求发出去到完整的服务器回包收完为止 =
发包大小/最低网速(主观 评估值)+服务器约定最大耗时(主观)+最大回包大小(由于无法事先获知回包大小(微信最大回包128KB))/最低网速(主观 评估值)+并发数 * 常量
由于 总读写超时 太主观,并且是一个差网络下、完整的完成单次信令交互的时间估值,因此其值通常都会显得过长,特别在网络波动或拥塞时,无法敏感的发现问题并重试,遂根据步骤进行拆分:
- 首包超时: 当发送数据大于MSS时,数据会被分段传输,分段到达接收端后重新组合,因此这里将首个数据分段到达超时定义为首包超时 =
发包大小/最低网速(主观 评估值)+服务器约定最大耗时(主观)+并发数 * 常量 - 包包超时: 两个数据分段之间的超时时间,这个时候因为服务端已经处理完成,不需要再计算等待耗时、请求传输耗时、服务器处理耗时 =
发包大小/网速(客观 准确值)+并发数 * 常量 - 动态超时: 分析网络状态,当趋于稳定的时候就减少首包超时,此时如果网络波动时我们预期它能够快速恢复,所以尽快超时然后进行重试,从而改善用户体验

心跳策略
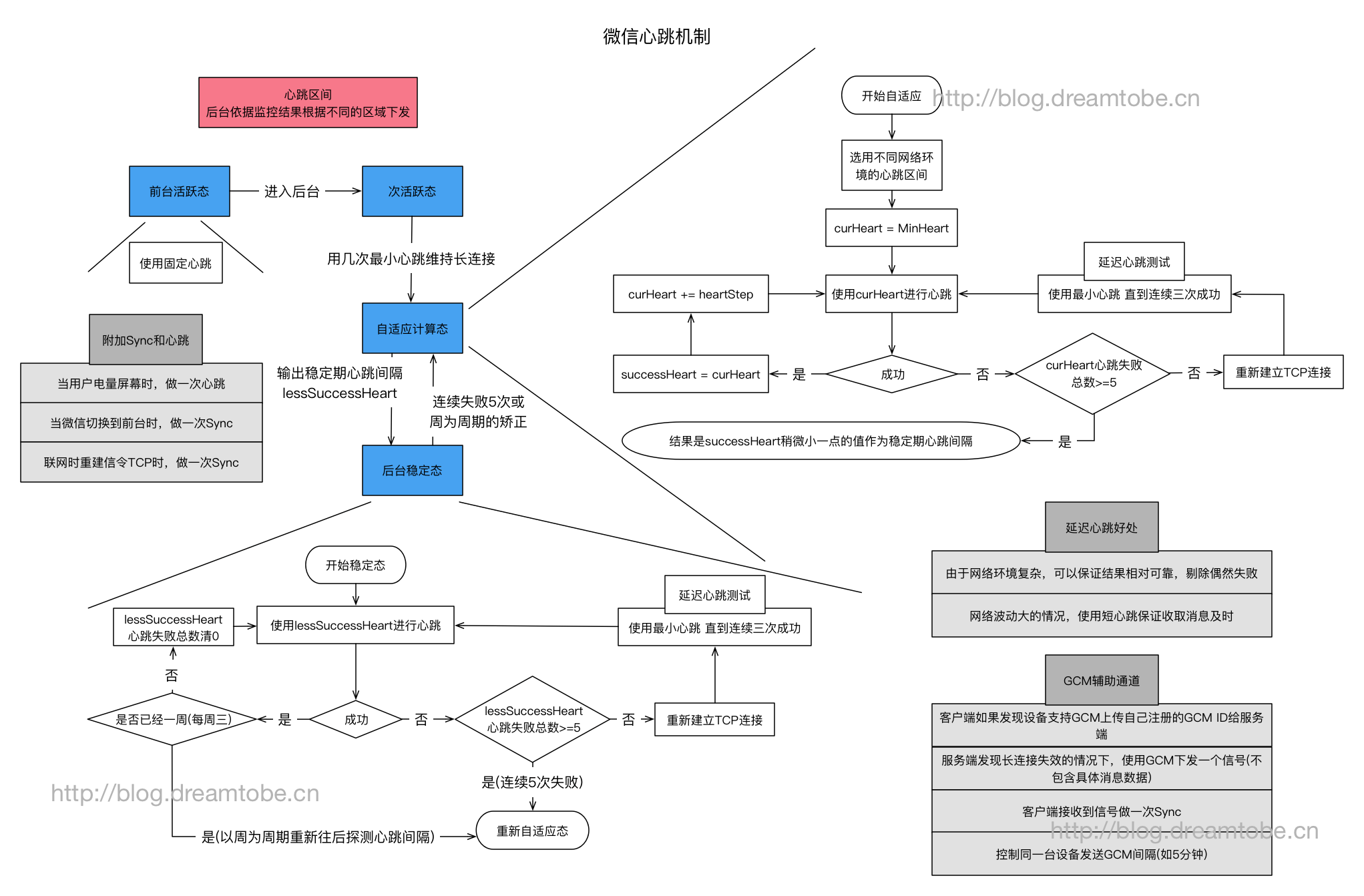
其中的有考虑到如何让手机更省电,因此有与Android的alarm对齐唤醒的处理(可以参见已经开源的mars的smart_heartbeat.cc)
II. XLog
高性能跨平台日志模块
所解决的问题
性能、可靠性、安全
- 避免频繁GC: 由于Native的实现,有效避免了频繁写文件造成的频繁的GC
- 避免频繁落盘的IO与加密: 达到一定数量日志了再压缩,压缩完再加密(由于短语式加密,如果先加密后压缩率会被严重影响)
- 避免丢日志: 将日志写入mmap中,避免程序被系统杀死不会有事件通知
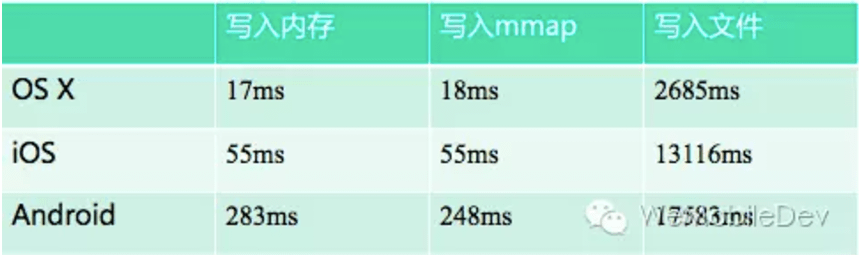
- 避免IO的耗时: 通过写mmap来达到写文件,其性能与直接操作内存相当
- 避免日志泄露: 在写入mmap之前就已经进行逐行压缩,并且写入前进行了加密
- 避免CPU短暂飙高: 采用多条日志流式压缩(日志行数累计到一定大小作为一个压缩单元进行压缩),压缩算法性能较高,由于每个单元的日志并不多,可以把压缩时间分散在整个分散周期内,CPU曲线更平滑
mmap
1. 引入mmap的原因
常规写文件所带来的问题:
写文件,系统是不会直接把数据写入磁盘,而是先把数据写入到系统缓存(dirty page),再根据策略将dirty page写入磁盘
dirty page写入磁盘策略:
- 定时写回(相关变量在:
/proc/sys/vm/dirty_writeback_centisecs、/proc/sys/vm/dirty_expire_centisecs) - dirty page的大小超过一定比例(调用write时检测,比例变量存储在
/proc/sys/vm/dirty_background_ratio、/proc/sys/vm/dirty_ratio) - 内存不足: 当内存不足时,就会block住当前线程
- 日志的场景: 日志的场景与普通的写文件场景不同,是断断续续,但是不断有日志
内容从程序调用,到写入磁盘过程: 用户空间内存 -> 内核空间缓存 -> 磁盘 ,因此涉及用户空间与内核空间频繁切换。应用层不可控,出现瓶颈。
综合频繁写文件会带来的瓶颈以及写入内存缓存带来的丢日志的问题(还有共享内存在Android 4.0以后便不再有权限使用),因此更好的解决方案mmap。
2. 什么是mmap?
逻辑内存对磁盘文件进行映射(不再有拷贝)
mmap带来的益处显而易见,操作内存 = 操作文件, 从而避免了 用户空间与内核空间频繁的切换,也正因为如此,我们只需要将日志写入mmap,就不会应用当前进程(/虚拟机)被杀导致日志丢失的问题。
3. XLog中将mmap回写文件的策略
- 内存不足
- 进程 crash
- 调用 msync 或者 munmap
- 不设置 MAP_NOSYNC 情况下 30s-60s(仅限FreeBSD)
压缩算法
为什么只使用LZ77中的短语式压缩
因为进一步的压缩(如自定义字典/huffman表)无法带来显著的效果,并且只要提供控制好压缩单元的长度,仅仅进行 短语式压缩 就能带来83.7%的压缩率。
压缩策略
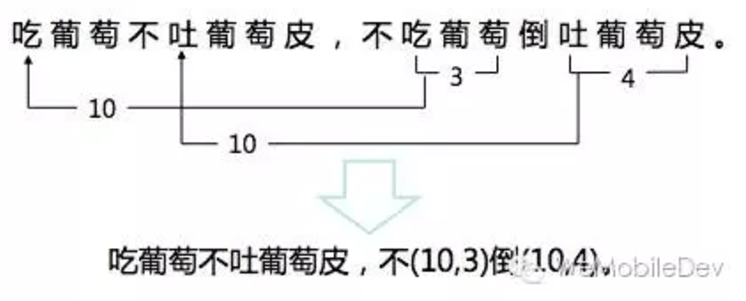
- 没被压缩的字符依然是ascci编码(整数表示),因此最终的压缩结果都是一堆整数
- 滑动历史缓存窗口: 一般是32kb,因此只需要一定大小的压缩单元就可以达到很好的压缩率,并非 大小越大的单元压缩率越大
- 采用分单元流式压缩,而非整个app生命周期内一起压缩,虽然耗时慢了许多但是由于耗时极小因此可以忽略,并且带来了很多好处:1. 个别的压缩错误影响面缩小到对应的单元; 2. 压缩时间分散在各个单元压缩时,因此CPU曲线更平滑
加密策略
考虑采用DH(Diffie-Hellman)。
- DH中有Ax, Ay, Bx, By。
- 其中通过DH算法:
DH(Ax, By) = DH(Ay, Bx) - 后端存固定的Bx与By,客户端存储固定的Bx
- 客户端生成Ax, Ay
- 客户端将DH(Ay, Bx)作为key,将Ax作为keybuffer
代码架构分层
XLog的代码主要分为三层
1. 收集层
该层主要与平台语言相关,主要是结构化日志
- format等处理在各类逻辑之后再处理,如有些日志级别我们不做存储,那么在这之前就不进行format
- format处理需要考虑有些内容中本身就包含了
%,如100%,导致format参数不足报错等问题,XLog中自己做了一层路由做这层处理
2. 接口层
这一层主要是C语言定义的对收集层暴露的接口
3. 输出层
将收集过来的日志进行处理,如落盘到文件、输出到控制台、输出到logcat等
也是对接口层的具体实现。
- 压缩与策略
- 加密与策略
- 落盘与策略
- 微信Mars:客户端跨平台组件的开发经验
- 微信Mars——移动互联网下的高质量网络连接探索
- 微信终端跨平台组件 mars 系列(一) - 高性能日志模块xlog
- 混合自动重传请求
- 微信终端跨平台组件 mars 系列(二) - 信令传输超时设计