为什么主线程的Looper,”死循环”取消息并不会引发ANR?
因为ANR是主线程中需要处理的各类用户输入,得不到及时响应才被触发。
因此即便Looper中只要在有消息需要响应的时候,及时被唤醒响应,便不会存在该问题。
Looper是怎么取消息的,采用什么策略?
这个其实在我的这篇文章中有分析到,如下图:
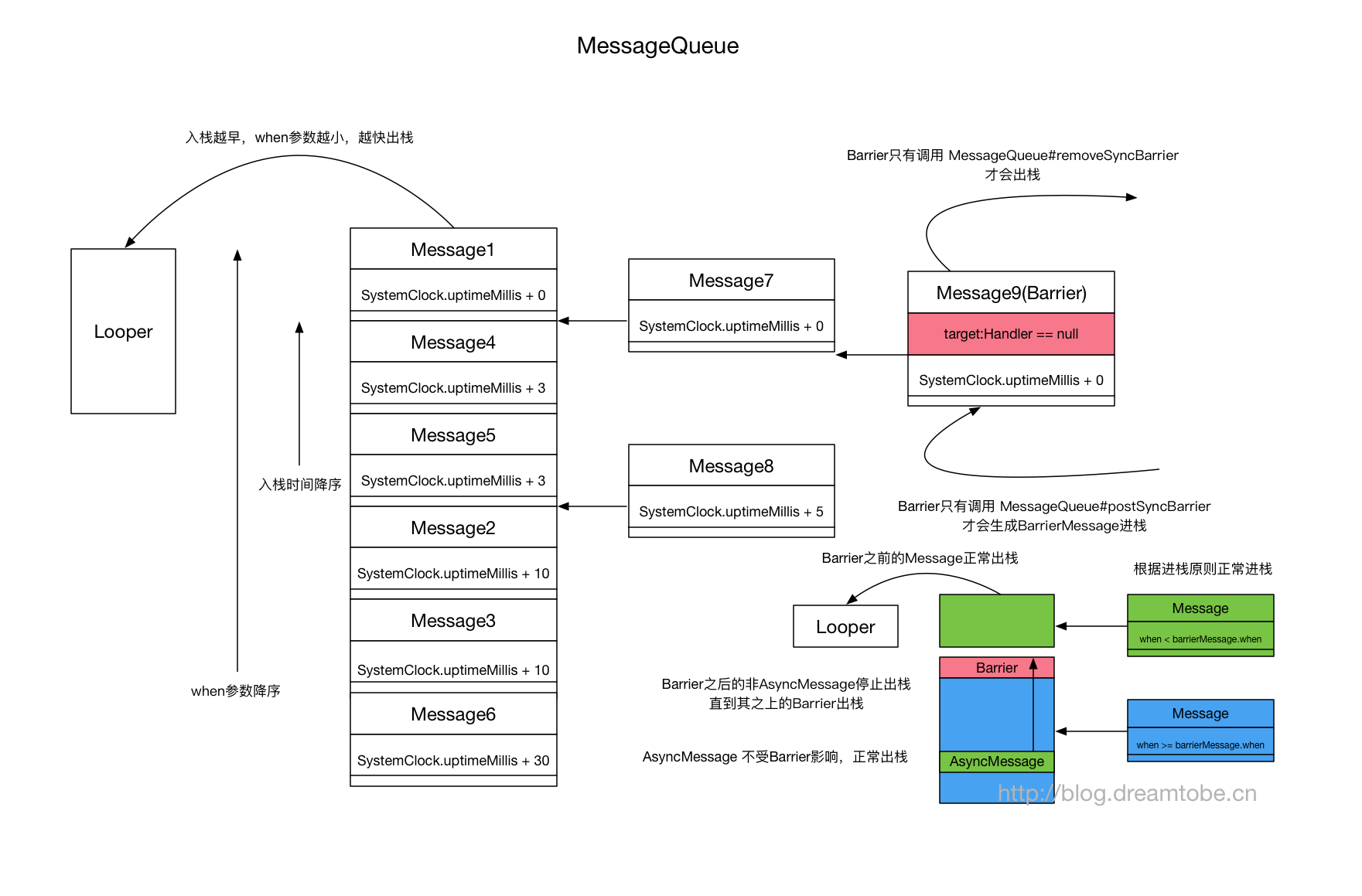
其取消息是通过MessageQueue#next()获取的,其出队策略并非始终从队头出。
首先MessageQueue的消息在入队的时候,会根据消息所带参数when的所代表的时间(单位为毫秒),进行入队并保持队列按照when进行升序排列;
而后出队是与是否存在Barrier消息有关:
- 如果存在
Barrier,Barrier之前的任何消息,按照时间升序逐一出队;Barrier之后的消息,只有isAsynchronous()为true的消息才能够按照时间按升序逐一出队 - 如果不存在
Barrier,任何消息,按照时间升序逐一出队
什么是Barrier消息,在Android中有什么应用?
Barrier消息是Message#target的值为空的消息,通常对上层是隐藏的,我们可以看到Handler带有async的构造方法是@hide的,而MessageQueue#postSyncBarrier与MessageQueue#removeBarrier都是@hide的,而Message#setAsynchronous也是在API22之后才对外开放。
Looper中是怎样进行休眠的,何时被唤醒?
休眠过程:
1
2
3
4
5
6
7
8
9
|
Message next() {
...
for(;;) {
...
nativePollOnce(ptr, nextPollTimeoutMillis)
...
}
}
|
1
2
3
4
5
6
7
|
void NativeMessageQueue::pollOnce(JNIEnv* env, jobject pollObj, int timeoutMillis) {
...
mLooper->pollOnce(timeoutMillis);
...
}
|
1
2
3
4
5
|
inline int pollOnce(int timeoutMillis) {
return pollOnce(timeoutMillis, NULL, NULL, NULL);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
...
Looper::Looper(bool allowNonCallbacks) :
mAllowNonCallbacks(allowNonCallbacks), mSendingMessage(false),
mResponseIndex(0), mNextMessageUptime(LLONG_MAX) {
int wakeFds[2];
int result = pipe(wakeFds);
...
mWakeReadPipeFd = wakeFds[0];
mWakeWritePipeFd = wakeFds[1];
...
mEpollFd = epoll_create(EPOLL_SIZE_HINT);
...
result = epoll_ctl(mEpollFd, EPOLL_CTL_ADD, mWakeReadPipeFd, & eventItem);
...
}
...
int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData) {
int result = 0;
for (;;) {
...
result = pollInner(timeoutMillis);
}
}
...
int Looper::pollInner(int timeoutMillis) {
...
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
...
}
|
唤醒过程:
1
2
3
4
5
6
7
|
boolean enqueueMessage(Message msg, long when) {
...
if (needWake) {
nativeWake(mPtr);
}
}
|
1
2
3
4
5
|
void NativeMessageQueue::wake() {
mLooper->wake();
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
void Looper::wake() {
ssize_t nWrite;
do {
nWrite = write(mWakeWritePipeFd, "W", 1);
} while (nWrite == -1 && errno == EINTR);
if (nWrite != 1) {
if (errno != EAGAIN) {
ALOGW("Could not write wake signal, errno=%d", errno);
}
}
}
int Looper::pollInner(int timeoutMillis) {
...
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
...
for (int i = 0; i < eventCount; i++) {
...
if (fd == mWakeReadPipeFd) {
if (epollEvents & EPOLLIN) {
awoken();
} else {
ALOGW("Ignoring unexpected epoll events 0x%x on wake read pipe.", epollEvents);
}
} else {
...
}
}
...
}
...
void Looper::awoken() {
char buffer[16];
ssize_t nRead;
do {
nRead = read(mWakeReadPipeFd, buffer, sizeof(buffer));
} while ((nRead == -1 && errno == EINTR) || nRead == sizeof(buffer));
}
|
什么是I/O多路复用?
也被称为”事件驱动”,如Looper中采用的epoll系统调用函数来使用该功能,休眠与唤醒当前Looper所在线程。
除了epoll外还有select、poll、kqueue等函数可以用来实现I/O多路复用,这里的”复用”指的是复用同一个线程,因为正常的I/O操作,是会阻塞住当前线程直到缓冲区中有数据,因此会霸占整个线程,而I/O多路复用则是通过同时监听多个描述符的读写就绪情况,配合非阻塞的socket使用时,每次都是系统通知描述符可读时,才去执行有效的read操作,让多个描述符的I/O操作都能够在一个线程内并发交替地顺序完成。
更多疑惑,欢迎评论讨论。