通过Scikit-learn编写一个HelloWorld
本文最后更新于:2017年6月23日 凌晨
上一篇文章中我们介绍了如何通过TensorFlow去训练一个识别数字图片模型,其中涉及了算法推演到最后的输出结果,其实可以借助Scikit-learn来简化。
I. 前言
一个简单的AI目的,如: 输入一个照片识别出是什么水果。
传统的做法我们需要写大量的代码来区分不同水果的特征,如形状、颜色等,但是AI可以通过训练Classifier来自动辨别而不需要我们编写。
II. 方案
通过scikit-learn这个库,可以采用Anaconda来一键安装所有scikit-learn的依赖(而且支持Windows、macOS、Linux等)。
大概的步骤: 收集训练的数据 -> 训练Classifier -> 结果验证
III. 编写helloword
安装完Anaconda之后,可以简单的编写python通过import sklearn然后执行下,验证下是否已经可以正常import。
1. 训练数据(表)
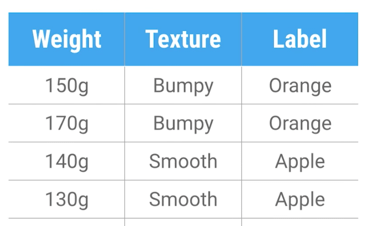
我们可以看到训练数据Orange比较粗糙也比较重,这里训练的维度就参考重量与纹理情况。
2. 代码
在编写时,将输入的训练数据1定义为smooth,将0定义为bumpy;将输出数据1定义为Orange,将1定义为Apple。
最后验证时,我们验证了[重量为150kg,比较粗糙的],输出的是1,是比较符合预期的。
1 | |
通过Scikit-learn编写一个HelloWorld
https://blog.dreamtobe.cn/scikit-learn-hello-word/