流利说客户端持续交付工程实践
本文最后更新于:2018年12月15日 凌晨
这块持续交付体系是一套比较系统化的、可靠的解决方案,也是我们这几年摸索沉淀的结果,希望大家都能够从中有所收益。
本文已经发布到英语流利说技术团队公众号,可请直接访问: 流利说客户端持续交付工程实践 - 流利说技术团队
本文所谈到的内容在GMTC上的相关演讲视频,可直接墙外访问: 流利说大前端持续交付工程实践 - YouTuBe
前言
今年6月底到北京参加了2018年的GMTC,分享了目前主要应用在我们Android这边的持续交付工程体系,今天抽空整理成文,希望能够与大家分享我们的坑点,欢迎大家多多拍砖,多讨论。
谈到持续交付,想必大家立马就能够联想到各类的持续交付系统,其实我们今天要分享的不限于此,不过持续交付系统是其中十分重要的一环,我们今天要谈到的具体来说是从代码提交到最终产品交付的一套体系化的节操控制体系,当然了,常规的灰度以及测试这块,我们今天就不谈了,我们更偏向于自动化与如何从代码层次解决产品质量问题。
其实不知道大家有没有发现,持续交付这块体系的文章一直以来相比于其他领域来说相对较少,我想主要原因是持续交付这块长期来相对比较杂,并且短期来看,除了基本的各类持续交付系统提供的基本的需求外,似乎产出比不是特别高,并且大多数公司基本上都是以大公司马首是瞻,当然总体来说,都是几类分流, Jenkins、 GitLab-CI、 阿里CRP平台以及Travis-CI或者是其他小众与自建的平台,由于英语流利说这边的代码是托管在GitLab平台上的,因此我们也是采用GitLab-CI用于持续交付工程的基础,下面咱们聊到的内容有很多会与其相关。
不过如果大家从长期来看,所有项目的代码质量与产品质量都有着至关重要的关系,随着项目逐渐变大,在迭代节奏不变甚至需要更快的情况下,甚至横向已经开始乳化新项目,这些都意味着团队人数不断变多,此时往往各类节操规则、文档、通过人员素质的约束将变得越来越困难,其中无论是个每位工程师的编码习惯,还是在代码架构逐渐复杂后,可能出现的各类隐藏的地雷,都是不可持续的。因此从代码提交到最终版本交付便成了保证代码质量,统一性十分重要的一个环节。
下面通过我们持续交付过程中具体的演进与实践与大家展开来分析分析。
I. 持续交付演进
常规的持续交付,我们可以理解为持续的交付各个版本的产出,我们就以这个为突破口来看看,持续交付工程具体可以是怎么样。
首先,我们想要随时打包,那么我们可以怎么触发它呢?
我们可以将代码推送到不同的分支来进行触发;我们可以通过提交 TAG来触发打包,比如我要打一个版本包,我就可以通过提一个版本的 TAG来进行触发;我们当然也可以通过设置定时器进行周期性打包,比如 Dailly-Build、 Weekly-Build,让QA他们能够更加Schedule的进行测试与验证。
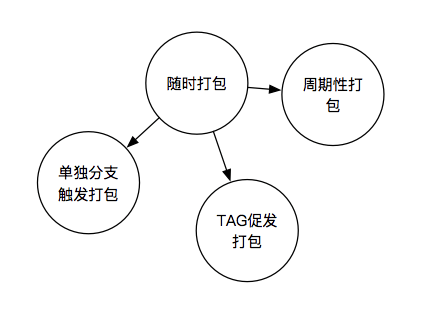
看起来似乎基本功能都有了,不过谈到持续交付,这里我们似乎还少了一块重点,我们想要可靠的进行出包,那么我们接着往下看。
很显然我们可以通过修改编译脚本,在每次打包之前都加入各类的扫描,来确保所出包的可靠性,现在看来似乎已经完美了。不过,实则其中潜在着很深的流程性的问题,原本出包是一个箭在弦上的事情,但是却因为在发包之前引入了扫描,使得整个发包流程受扫描影响,节奏被极大的打乱,特别在于反反复复扫描出问题的情况,我们不得不在出包的节骨眼,来来回回的找相关的工程师进行修复问题,然后再触发打包,可能又扫描出了新问题,又要找相关的工程师进行修复,再触发打包,反反复复,使得出包变得非常的低效。
那么我们应该如何去解决这个问题呢?
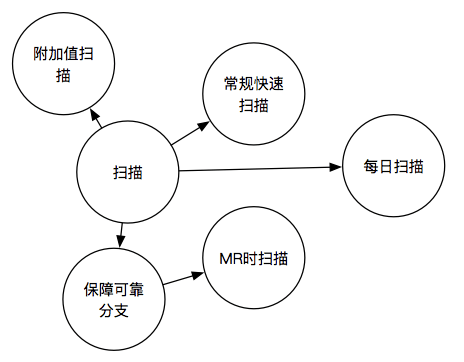
我们将策略进行调整,改为在MR的时候就引入扫描,确保MR的时候扫描通过了,相关的代码才能够被合入对应的分支,以此来确保远端存在可靠的分支,比如 develop、 master与 release分支都是我们可靠的分支,这么一来在这些分支上便可以直接进行出包了。
但是不久我们又发现了新的问题,那就是如果在MR的时候就引入了大量的繁重的扫描,原本MR的环节就会因此变得十分的冗长,于是我们将原有的扫描拆分为了三类: 常规扫描、 每日扫描与 附加值扫描。
常规扫描就是我们前面提到的MR时必须通过的扫描,这块扫描,我们约定是十分轻量的以及十分必要的扫描部分,比如Android官方推荐的 AndroidLint、 UnitTest,而由于 AndroidTest需要跑模拟器对每个模块甚至需要独立打包,我们将其放在了每日扫描中,其他方面,如对源码扫描的 PMD以及确保统一代码风格的 CheckStyle我们也将其放在了常规扫描中;而类似的对 PMD有一定的互补作用,但是对编译结果进行扫描的 Findbugs我们将其放在了每日扫描中,而包分析与安全扫描我们将其放在了附加值扫描与每日扫描中。
我们前面提到了分支、MR等,为了确保持续化交付可靠的出包,我们这边就不得不提到版本管理。
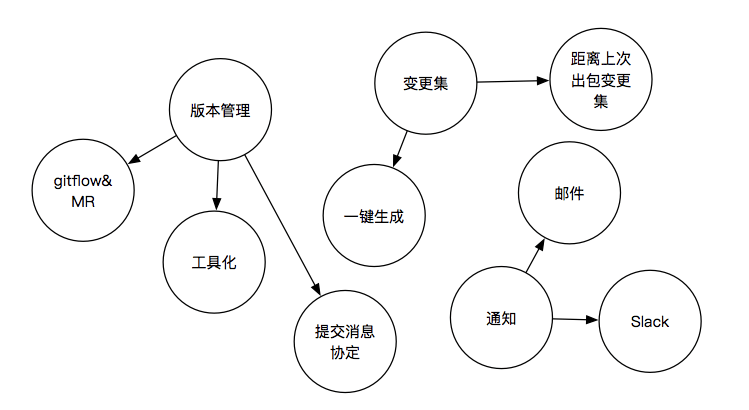
其实客户端这边的版本管理,和前端与后端有很大的不同,前端与后端的版本部署可以是一周、半周甚至2天,发布窗口非常密集;而客户端这边的版本在线上的停留一般是半个月,一个月甚至是一个多月,整个周期相对较长,所以有整个长周期的灰度环节,有 Alpha、 Beta、 PreRelease、 Release来确保版本发布的可靠,因此为了保证整个版本管理更加可追溯以及整个发布流程更加可靠,我们自己总结了一套 LingoChampProductionFlow(下文会提到)。
在版本管理这块,我们发现其需要涉及到需要落实到每个工程师上,如果是通过文档进行约束与落实是十分低效的,因此我们开发了 Lit来将其进行工具化。
对于 CommitMessage这块我们认为对于后期的追溯以是非常重要的,因此我们引入了一套提交协定(下文会提到)。
在引入提交协定之后,我们发现我们其实可以做的更Make Sense一些,我们发现在每次工程师进行提测的时候,都不得不对QA描述清楚当前这个包距离上一个包修改了哪些内容,让QA同学对其进行测试,因此我们基于我们约定的提交协定将这块变更集改为了自动化,在每次出包的时候会自动输出距离上一个包的变更集,并且支持了对其一键生成。
我们前面提到了出包、每日扫描、变更集等,其实这里就有一个十分重要的环节,那就是闭环,也就是通知。
如果你们公司有用于发布内部包的工具,那么直接将包与变更集自动发布到上面是Make Sense的,如果没有,也可以简单的通过聊天工具的 WebHook通知到相关的聊天群中(比如Slack、企业微信、钉钉等都有支持),而对扫描的质量报告我们更偏向于通过邮件进行沉淀。
其实上面我们提到的这么多,都是其应用层,其实做持续交付到后期基建部分会显得愈发重要。
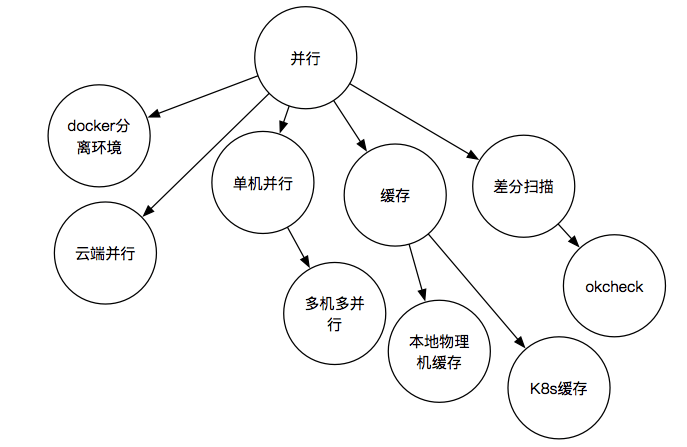
我们会发现上层的工作越来越多,不但每次MR的时候需要进行各类的扫描,还需要支持随时的出包、出变更集甚至随时面临横向各类新应用的不断地接入,原本单一的串行持续交付体系已经不足以支撑,因此紧接着我们开始做并行。
刚开始的时候,我们做了单机的并行,由于单机的资源有限,而不同的任务需要的资源又不同,紧接着我们便开始做多机并行,期间我们发现如果在同一个环境下有多个 Java进程共享 Gradle缓存,就会存在很多因冲突导致的问题,也是为了更好的横向部署,我们开始通过 Docker对环境进行隔离,可是隔离之后虽然解决了资源冲突的问题,但是又由于缓存无法共享,导致每次冗余的资源拉取,十分的耗时,因此我们这边开始做了一套基于 Docker的缓存复用机制,渐渐的我们本地有了7个稳定的可用本地的并行。
紧接着由于我们内部Cloud Infra团队可以为我们提供k8s,因此我们在本地7个并行都吃不消的情况下,我们会启用k8s的云端动态部署,我们甚至基于云端的特性也搭建了另外的一套缓存复用机制。不过由于云端动态部署的策略原因,每次使用前都需要申请机器,部署机器,拉取image等环节,启动流程会比本地慢不少,因此我们将云端方案作为本地的备选方案。在这个期间我们还做了基于版本管理的差量扫描并进行开源 lingochamp/okcheck来环节扫描的压力,后面我们会稍微提下。
对于上面提到 Gradle缓存这块,理论上是有几套解决方案的,比如可以直接将缓存打入 DockerImage中,但是很显然这样会引入一些问题,比如image大小会持续变大、image需要持续更新、image与项目耦合等,综合下来这个方面并不是特别的好;还有一种是通过架一套缓存服务或者是通过映射同一个目录,这种简单粗暴的做法显然又引入了冲突的问题,因此最后我们做了一定意义的定制,对于本地机器而言,我们采用映射目录,不过根据其运行特征,每台机器同时只能跑有限的任务,因此我们只需要维护有限的缓存目录即可,如下图,我们将原本的缓存复用逻辑调整为选用可用的缓存目录来解决。
而对于云端的缓存,我们的做法是提供了局域网内的Nexus服务,这台Nexus对所有用到的缓存做了一层代理,因此云端上的运行时每次对局域网中的依赖拉取使得这块的缓存复用的问题在一定意义上得到了解决。
II. 持续交付实践
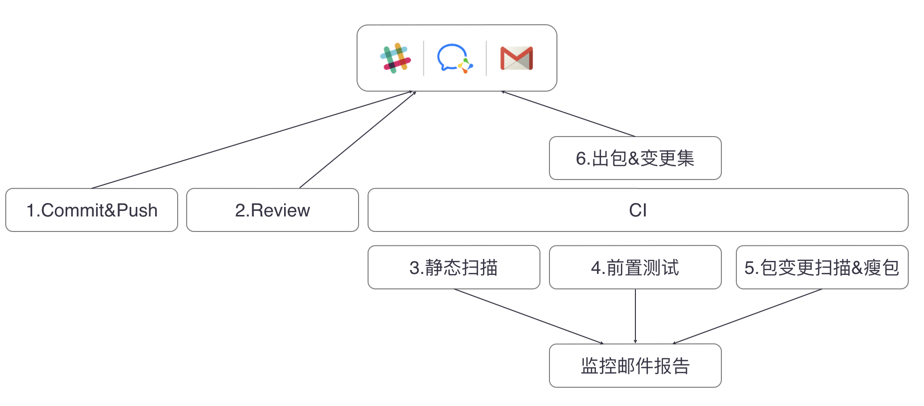
我们现在就可以把整个持续交付工程很清晰的分为三块:
- 第一块为
Commit&Push,这块主要通过版本管理与提交消息的协定来保证版本发布的可靠性与可追溯性 - 第二块为对 代码的
Review,我们认为代码Review是十分有必要的,相关的MR至少要经过一个同学Review才允许被进行合入操作,并且我们十分欢迎Review时对代码进行评论,因为这将十分有益于对代码的打磨,对于Reviewer来说,在Review过程中不仅仅能够看到业务的问题与逻辑,更多的是能够与其他工程师交流,碰撞不同的架构的思想,并且一些架构潜在的规范也能被有效的践行 - 当然对于代码质量,以及其存在的一些问题,我们更依赖于第三块的静态扫描,所以我们在CI这块做了很多必要的自动化的事情,包括静态扫描、出报告、单元测试集成测试的覆盖率的计算,甚至我们还合并了QA手工测试的动态覆盖率报告的计算,还有打包、发邮件等等。
我们接下来就具体来谈谈其中的一些细节。
1. Commit Message
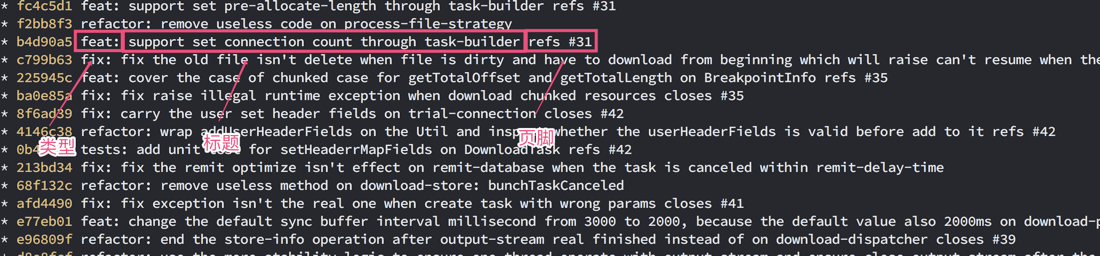
我们采用了 AngularJS的消息协定,这块协定比较清晰简单,其主要分为几个部分: 类型、 区间、标题、主体与页脚。通常对我们来说,我们在其基础上做了一些简化,我们认为一条最简单的 CommitMessage只需要包含类型与标题即可,其类型已经说明清楚了该条 Commit是: 需求、 修复、 重构还是 文档编辑亦或是 集成维护、 测试编写等,内容方面我们也没有强制一定要使用英文,不过如果使用英文我们有根据协议要求标题部分尽量使用一般现在时以及尽量不要出现驼峰单词以及 .的标点。
2. 版本管理
对于版本管理这块,其实我认为在满足稳定可靠发布的前提下,越简单越好,因为这套体系一旦复杂化就会显得非常的流程,并且十分容易引入内耗,因此对于我们内部各个团队共享的非线上产品项目,我们内部是直接使用 GitLabFlow,这套流程既能够保障仓库 Owner能够快速的在 master分支上持续交付版本以及提交代码,也便于其他同学更快,更可靠的通过MR参与迭代。
但是,对于线上长周期的产品考虑到整个发布流程可靠与稳健,我们前面也提到了,我们出了自己的一套 LingoChampProductionFlow( LingoChamp是我们英语流利说开源库的 Group的名字),如图:
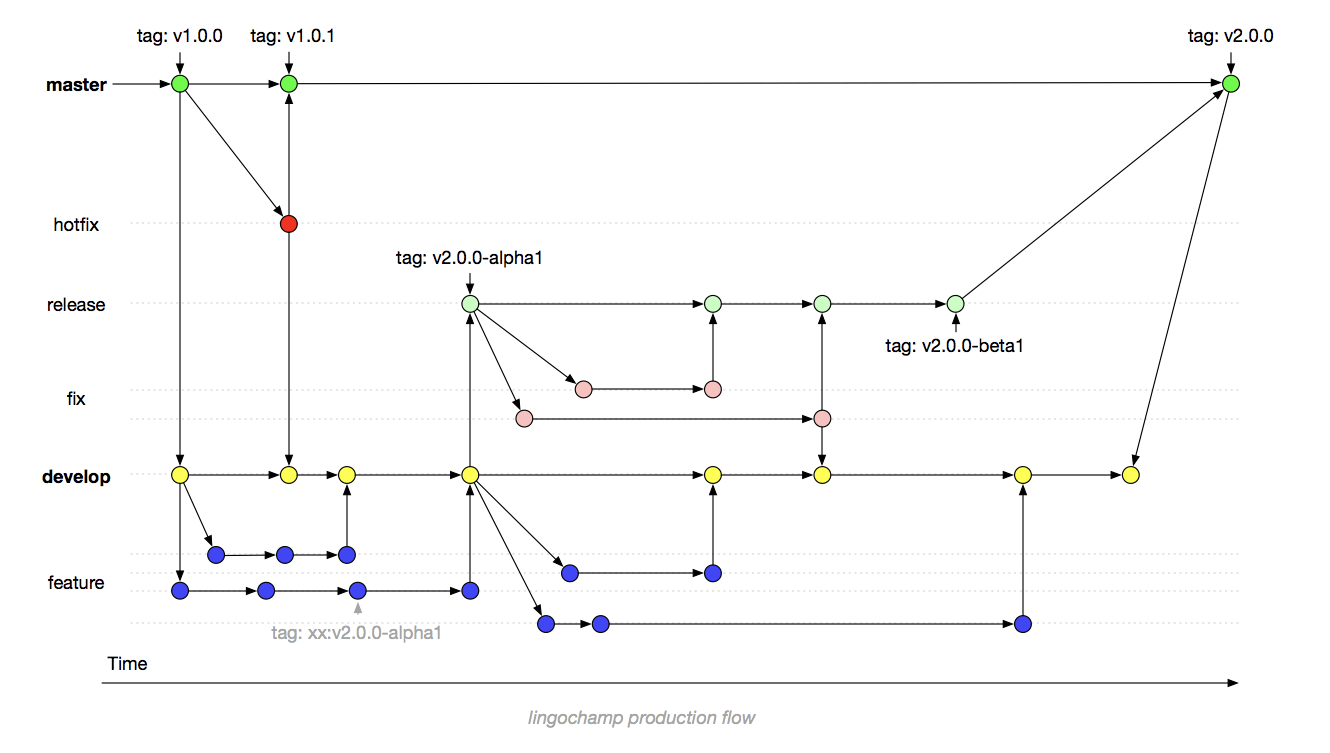
可能有些同学已经发现了,这似乎是 GitFlow的变种,这套流程确实是基于 GitFlow,不过我们根据实际开发过程遇到的问题,进行了一些调整。
首先 master分支只会在每个版本发布的时候才会进行合入,是一个极其稳定可靠的分支,绝大多数同学都没有该分支的操作权限,并且该分支是严格受保护,不允许覆盖操作的,通常来说你可以在 master分支上找到所有的版本点,并且其 HEAD也应该与上个版本的 TAG处在相同的 CommitId上。
从 master分支迁出的 devleop便成了持续开发的基础,不过绝大多数同学依然是没有 develop分支的直接 push权限, develop分支依然受到严格的保护,大家无论开发需求、修复问题还是重构,无论是长周期需求,还是短周期需求等等都是从 develop分支迁出自己的 feature分支进行开发(如 feature/okcheck-integration是我迁出来一条用于集成 okcheck的分支),当开发完成后提交MR合回 develop即可,此时通常只需要相关的 CodeOnwer审查通过以及静态扫描通过的情况下即可进行合入操作,当然你也可以在 feature分支上直接通过打上 TAG来触发打单独需求的提测包,出包的同时,我们会一起带上该分支从拉出到出包的变更集。
当 develop迭代到一定阶段后,我们开始对该版本进行提测,提测的概念就是接下来不在会有新需求的迭代,只会有问题的修复,此时我们从 develop分支迁出 release分支,迁出后 develop分支便立即进入下个版本,这样的方式是应对各类并行开发导致的问题以及通过独立的 release分支可以对提测后的分支进行更严格的保护,因为此时该版本离正式发版已经非常近了,这个节点通常至少已经度过了整个版本周期的半程。此时需要在 release分支上对该版本提测后发现的问题进行修复,便直接从 release分支中迁出对应的 fix分支(如 fix/score-crash是我迁出来修复打分奔溃的分支),修复完成后再合入 release分支,此时的合并除了需要 CodeOwner的审查与静态扫描通过外,通常情况还需要发布经理的同意,以确保该修复是否需要在该版本带上。当然在 release分支上可以通过打 TAG来驱动整个灰度流程,如 v6.1-alpha1、 v6.1-alpha2等等,在打完 TAG后,整个出包机制会自动触发并且带上相关变更集。当 release分支完成提测后,我们将 release分支合入 master分支与 develop分支,通常来说到此便完成了整个版本发布的闭环。
最后还有一个 hotfix分支,是当线上版本遇到问题需要紧急发包修复时,我们此时从 master分支迁出 hotfix分支,并将问题修复发布版本后合入 master分支与 develop分支即可。
3. Code Review
代码审计这块,我们是依赖 GitLabCI的MR机制,我们配置了至少需要1个 Approvers,并且只有在所有的评论都被解决以及 pipeline成功后才允许进行合入操作。
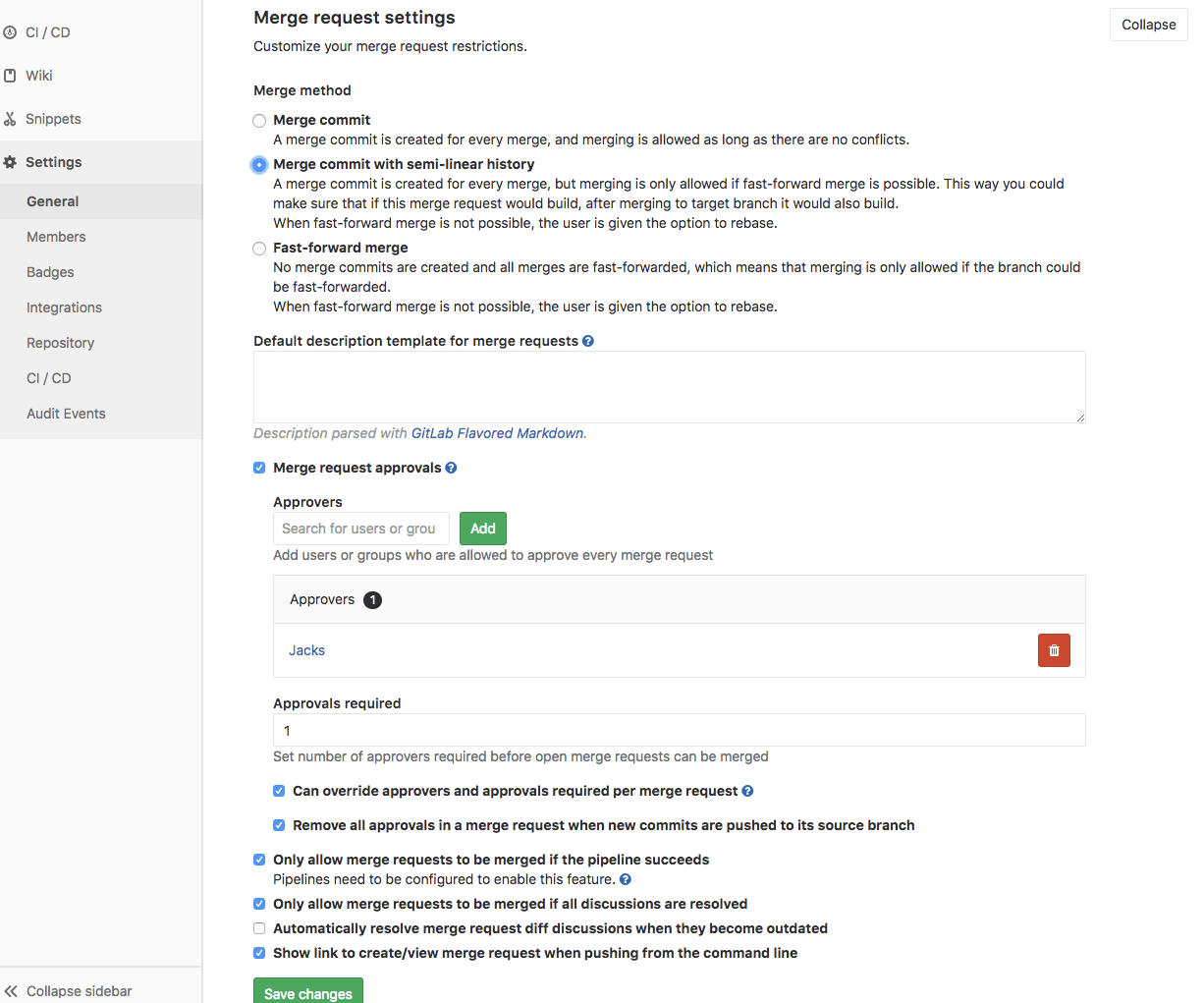
如下图,受益于 GitLabCI完善的 Review机制,这边涉及到几个十分必要的功能点:
- 第一个点是:支持对每行代码进行评论并对评论后将其自动标注为需要解决的状态,以及对整个MR的评论的基础功能
- 第二个点是:在提交MR的时候支持配置目标
Approver是哪几个同学以及Reviewer是谁,在对项目进行配置的时候也可以配置强制至少需要哪几个同学进行同意 - 第三个点: 就是那个
pipeline,大家从下图可以看到那个合入按钮目前的状态是Mergewhenpipeline succeeds,这里的Pipeline就是在执行前面咱们提到的常规扫描,这按钮的状态说明,只有在那个扫描通过了,Reviewer才被允许点击Merge进行合入操作
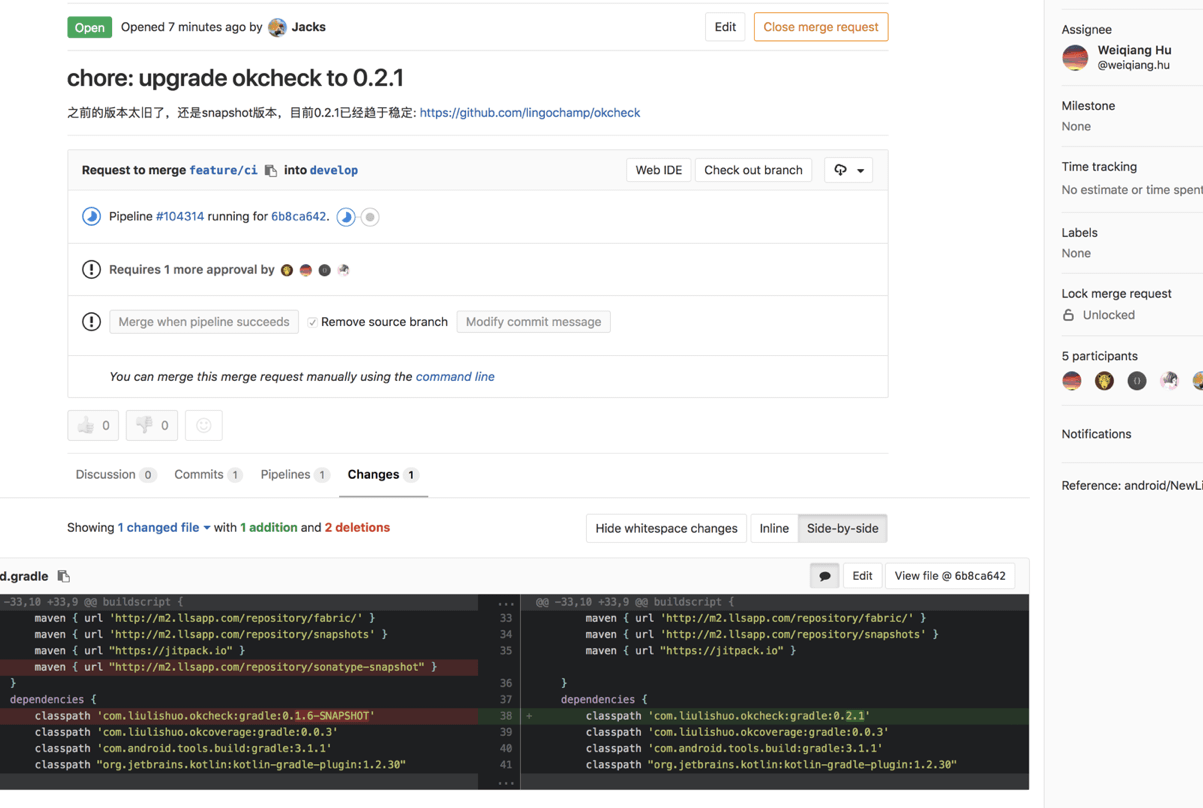
如下图,其Pipeline正在跑当前MR的扫描:
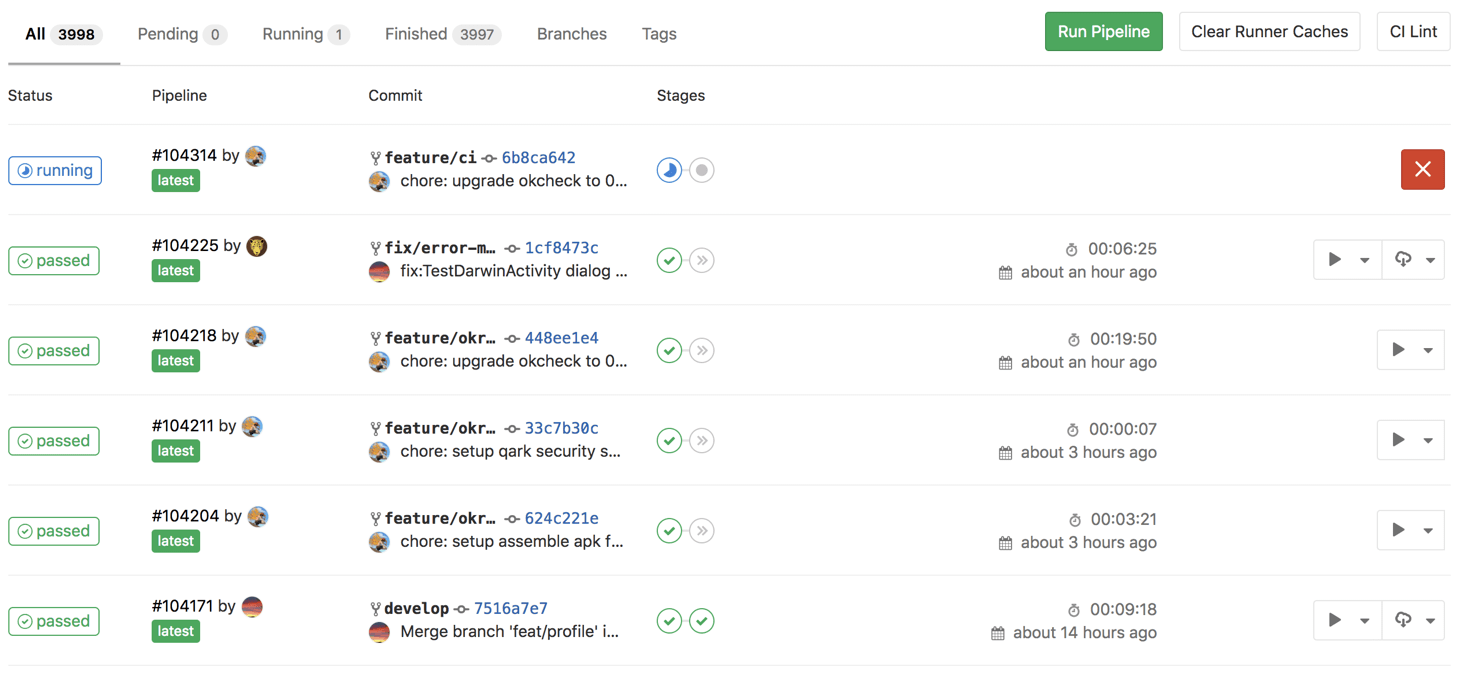
我们继续点进去会发现其跑的过程以及右侧的Job artifacts有其扫描的整个耗时情况(以避免有些同学单元测试写的存在问题照成不必要的耗时没有被暴露)以及修改建议报告提供下载:
GitLab的这套MR机制,其实就能够以极低的学习成本让工程师们了解到该MR可以做的事情,以及需要完成的事情,整个流程潜移默化的保障了整个合入的操作的可靠性,首先是常规扫描的通过,其次需要 Approver的同学对代码的 approve,最后才是 Reviewer对代码的合入操作。
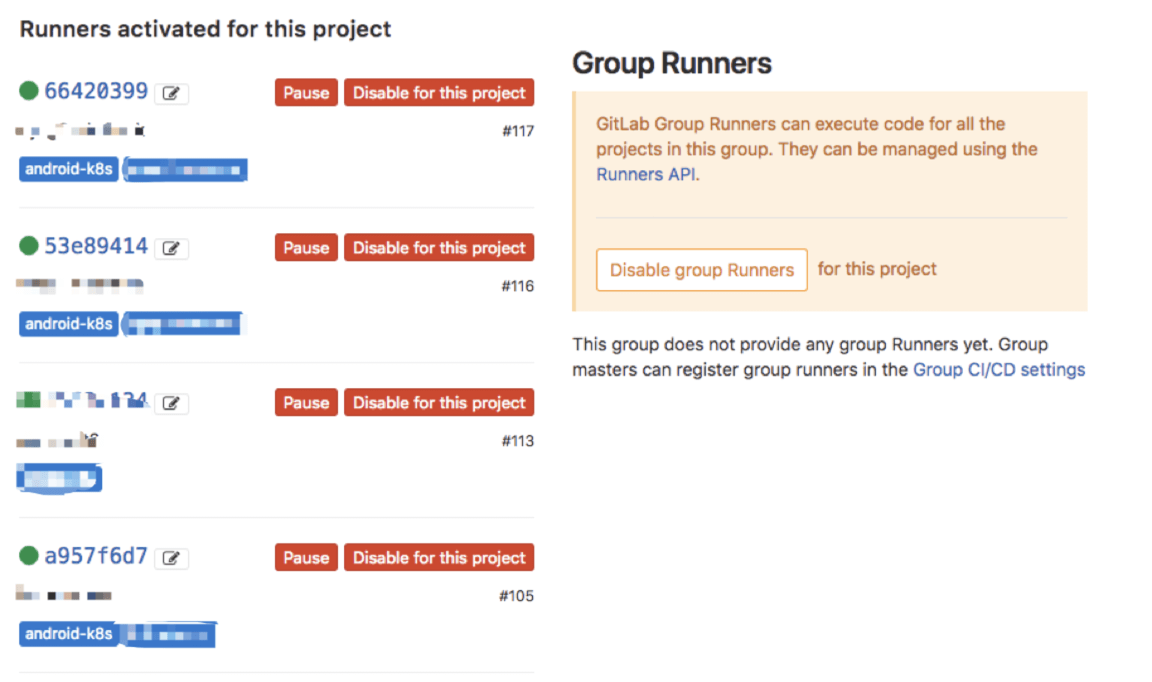
4. Gitlab与Runner的搭建
其实这块大家直接参看官方文档即可,无论是 GitLab本身,还是 Runner的搭建都是极其的简单的。其中 GitLab就是用于仓库托管的,而 Runner就是每个 Pipeline所跑在的具体环境与机器,其与仓库托管的机器通常是不同的机器。大家在搭建 GitLab建议可以直接使用 Omnibus这个版本,基本上几个指令就可以搞定,当然网络上面相关的教程也很多。
而对于 Runner配置这块过程,大家直接通过编辑其 toml即可,通常Ubuntu系统是在 /etc/gitlab-runner/config.tmol目录下面,如下图我们的一个配置案例:

而对于对同一个Job配置多个并行Runner的方法也有许多,比如我们采用多个Runner使用相同的TAG来达成:
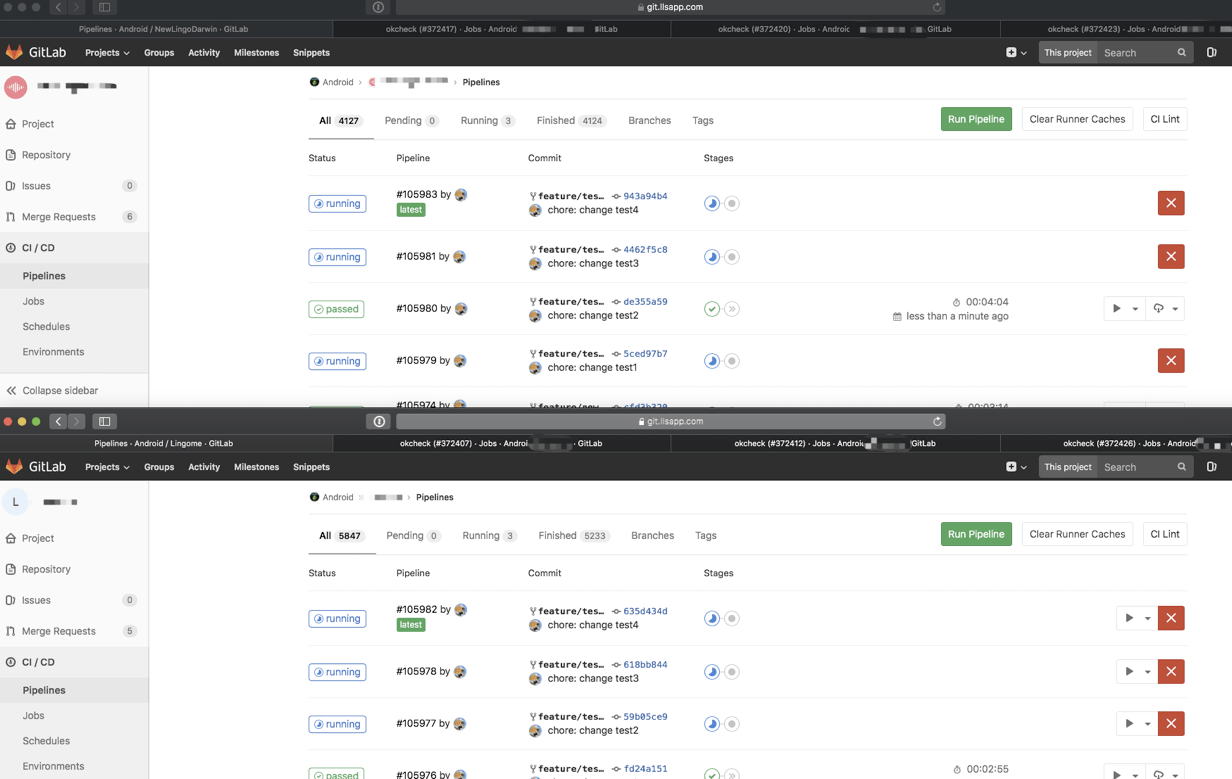
而 DockerImage这块,我们本地的机器上面由于映射了 sdk的目录无需多做适配,云端上面由于k8s的维护不在我们这边,我们直接提供与 sdk挂钩的不同环境的 image。
由于篇幅原因,CI机搭建这块我们不细做展开,这块网络上面文档也比较多,主要是通过项目的 gitlab-ci.yml文件来配置不同的 Job,而通过 Runner的 config.tmol文件来配置每一个提供的 Runner的环境,每一个 Job都是运行在指定的 Runner里的。
5. 多人维护与安全
多人维护CI这块,相信每家公司都有自己的做法,这块的考量主要是安全与灵活性的权衡。有些公司可能会搭建独立的一个平台来运作这块,不过我们这里提供了一个相对简单的方式,我们直接通过 GitLab的权限管理,创建存储不同CI配置的仓库,再在CI机上面创建对应的定时器,每分钟检查一遍相关仓库 master分支上的内容,以此将原本复杂的需要多人登录CI机对不同的配置文件进行配置的问题,简单的演变为了不同包含配置内容仓库的MR,从而通过最小的开销解决了绝大部分场景下的多人CI机维护的问题。
当然对于CI这块还有很多安全相关的,比如我们的热部署的 Runner就做了项目的限定,甚至做了分支限定,再结合 GitLab上用户权限的管理确保其安全性。
另一块案例是我们对于第三方依赖库的基线的透明化处理,这也是很多项目所遇到的问题,这个问题在于项目中由于包含各类第三方库的依赖,而其实对于第三方库的版本调整是十分敏感的,但是除非相关 Reviewer其第三方仓库的版本变更很难被探知;我们希望对于依赖库的版本调整是灵活的,但是我们又希望这块其是敏感的,可被探知的,因此我们使用 GitLabCI做了一套基线控制机制。首先,我们通过MR时的扫描严格约束了所有的依赖库的申明必须在 gradle/baseline/baseline.gradle中完成,并且所有的引用只能通过访问申明的形式进行引用;其次,我们创建了单独的 baseline项目,并通过 subtree的方式链接到了 gradle/baseline;最后我们确保, gradle/baseline这个单独的仓库每次拥有变更时都会通过 WebHook直接通知到相关的Slack的Channel中,并且每天会自动做一次 subtree的 push,以此便十分灵活的以最低代价的解决了依赖库不透明的问题。
6. 静态扫描
这块是基于我们已经开源的LingoChamp/OkCheck,这块大家可以通过项目的README以及下面的一个视频进行快速接入:
OkCheck主要是简单易用,基于 CommitId的差量扫描以及快速集成,默认情况下集成了 AndroidLint、 UnitTest、 PMD、 FindBugs、 KtLint、 CheckStyle等,在主动配置后还可以开启 AndroidTest以及覆盖率的计算。更多内容大家可以直接通过集成进行验证。
7. 触发形式
触发这块,正如前面提到的我们这边分别采用了周期性促发,提 TAG触发以及强制触发的几种形式,周期性任务直接通过 GitLab-CI中的 CI/CD=>Schedules中配置即可,而 TAG形式与强制形式直接通过配置项目根目录的 gitlab-ci.yml文件即可,相关内容可以直接参见官方文档。
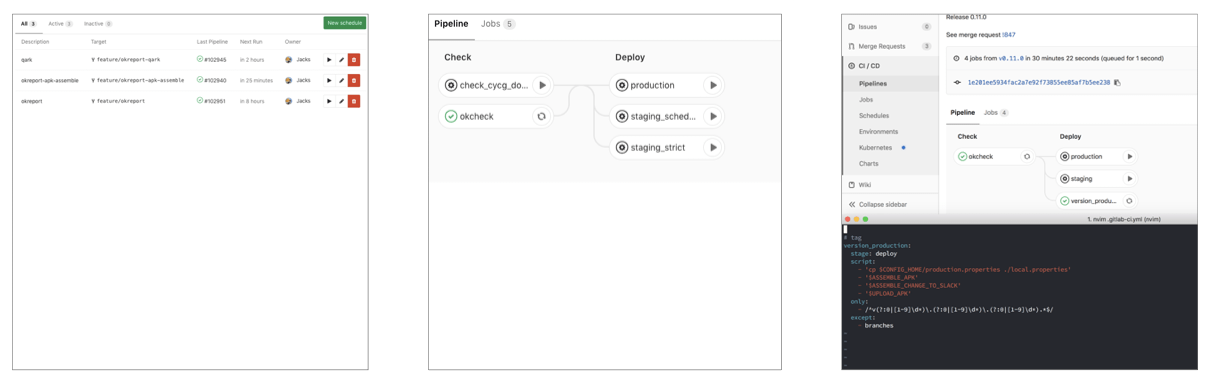
8. 报告与闭环
首先,首当其冲的闭环就是出包时的变更集,这块就是简单的基于 CommitId对 CommitMessage分析,简单且带来不错的收益,如图:

不过目前内部我们在做一套更强大的Lit系统,其的变更集会与包一起通知到我们新的用Flutter写的内部包发布应用上,后续我们会考虑对Lit进行开源。
而另外一块质量报告主要基于我们的OkReport项目,OkReport项目主要是依赖前面提到的OkCheck的各类报告的输出,并且做其他的安全分析以及基于 ApkAnalyzer的包分析以及覆盖率分析等。OkReport我们后续也会考虑开源到我们github上LingoChamp的Group中,大家可以持续关注。其相关的报告我们会分为 DailyReport与 WeeklyReport两种。 DailyReport这块我们只会将相关的报告通过邮件发给相关的同学,而 WeeklyReport我们则是将相关报告发给更高级别的同学,并且我们会在Android工程师每周的TechTalk上回顾整个一个质量的变化,我们希望以此能够让大家更加重视代码质量。当然了除了安全扫描,包分析,各类质量扫描(如线程问题、最佳实践问题等等)以外我们目前还欠缺渲染帧率的变化的监控等,这些都是现在的质量平台所需要考量的,后续我们也会逐渐对齐进行完善。
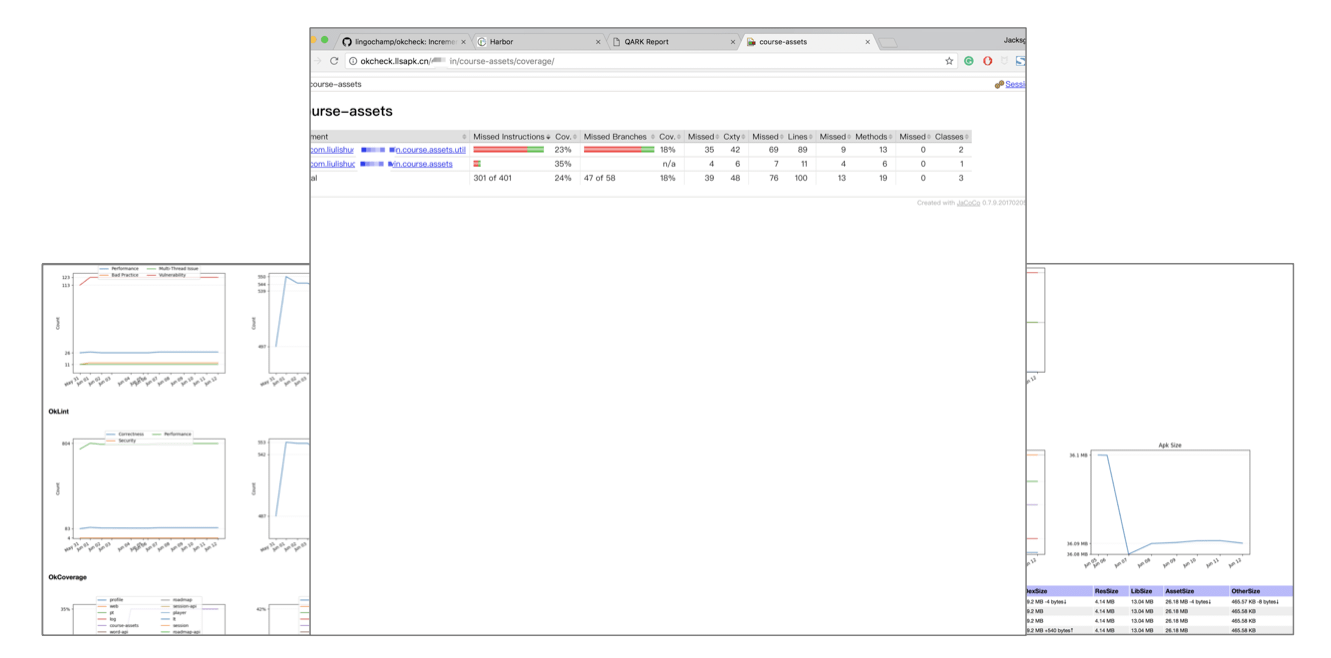
9. 避免线上裸奔
这个也是我们在CI环节正在引入的一套措施,是我们内部OkCoverage这个项目主要做的事情,我们通过计算每天扫描的 单元测试 + 集成测试 + 人工测试这三者合并后的代码覆盖率是否最终达到 100%,以此为版本可发布性提供依据,反向推动更可靠的单元测试编写以及QA测试测试时的相关指标的完善。

III. 回顾
我们通过工程师的视角来简单回顾下这套持续交付的大概的形态。
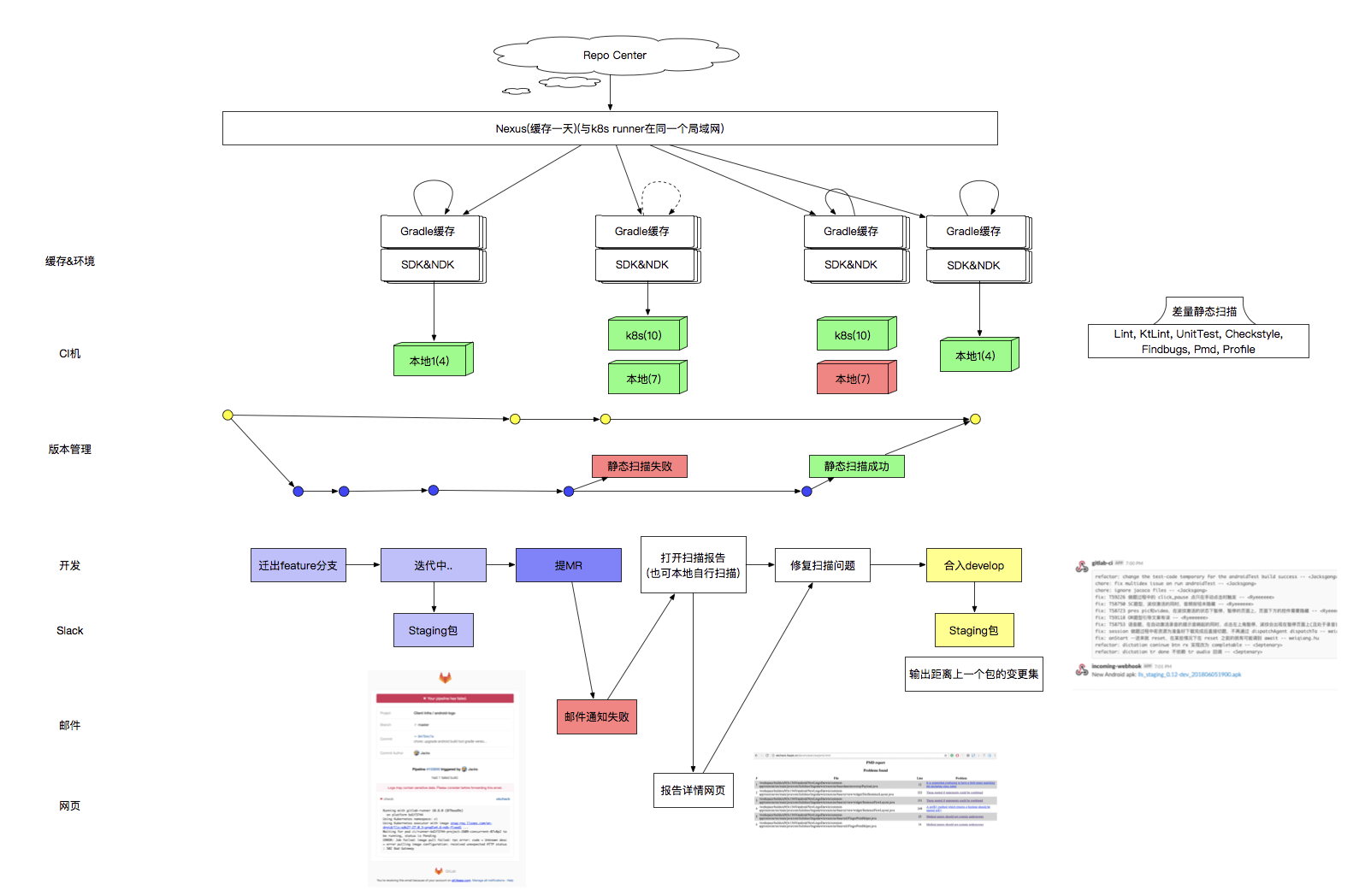
工程师从 develop分支迁出自己的 feature分支进行迭代,在迭代过程中不断的向自己的 feature分支提交代码,当觉得可以对该需求进行提测时,在其分支上打出对应的Staging包,并提交测试,在测试后完成需求开发,此时提交MR到 develop分支,但是常规扫描发现其中的十分隐蔽的问题,此时该工程师收到邮件通知,下载修改建议报告以后,根据报告建议对代码进行调整,重新提交,此时扫描通过,相关同学 Review通过后便可合入 develop。
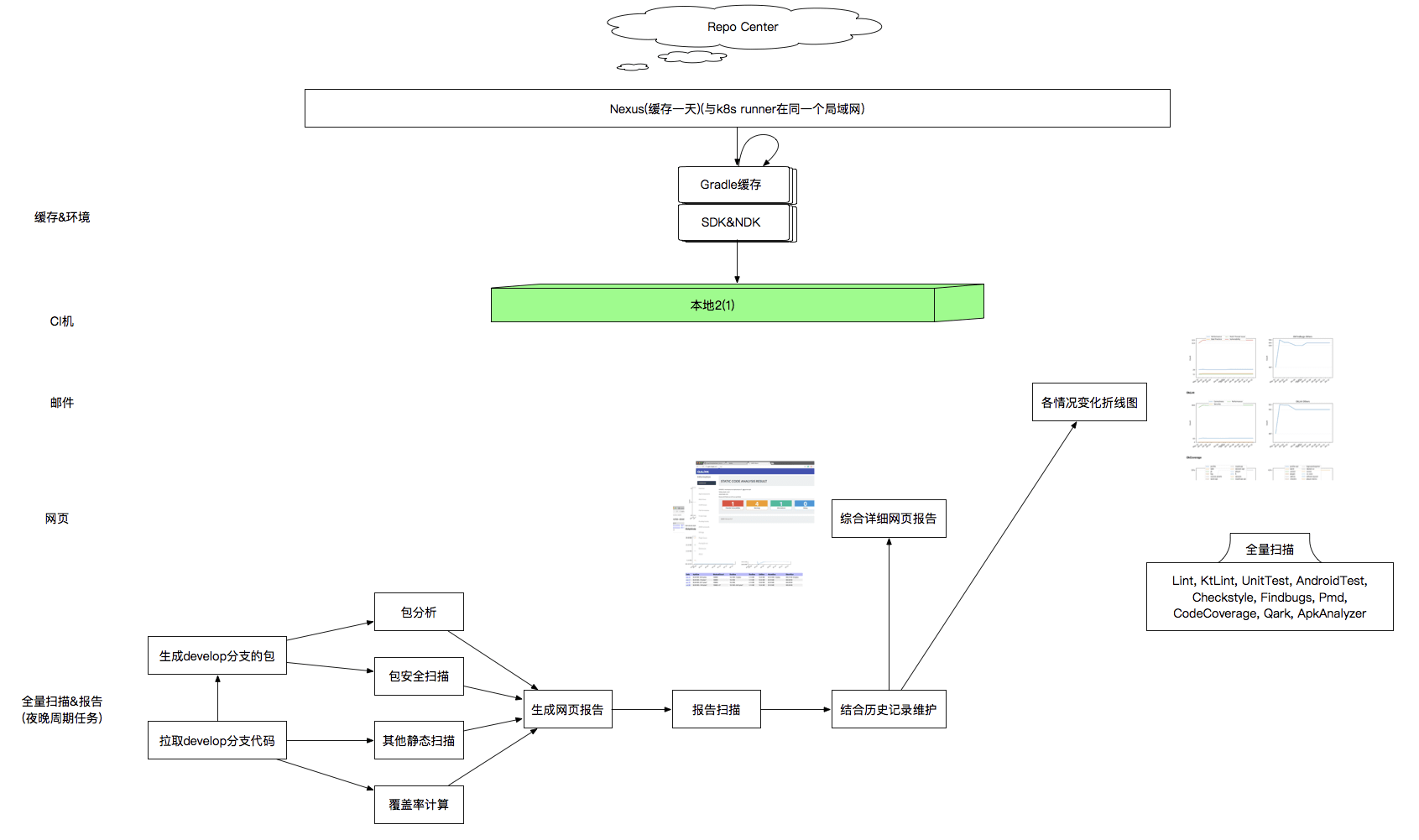
而在夜晚的时候,我们通过 OkReport进行更加繁重的全量扫描以及各类的包分析,安全扫描等,在上午时将邮件发出,并刷新到质量平台。
IV. 反思
最后,在整个持续实践的过程中,能够深刻感受到,持续交付这块是极其容易引入内耗以及流程的环节,希望大家如果目前正在做或者将要做这块事务的时候,能够坚守做正确的事情,确保整个流程尽可能透明,轻量以及尽可能减少其学习成本,将其系统化、高效化以及自动化。持续交付这块一直都是比较杂,并且没有一套最好的或者是标准的解决方案,每个公司可能根据其情形会有所不同,也欢迎大家多拍砖,多讨论。